Google Feed Recommends Illegal Gambling Sites to Me
If you use an Android device or the mobile Chrome browser, you’ve probably seen the recommended content on your home screen’s Google feed or browser’s main page. This feature provides personalized content based on your search history, location, and interests. I frequently use this feature to stay updated on various news topics.
However, at some point, I started noticing suspicious domain content being recommended in my timeline. These contents initially appear legitimate, often masquerading as informative articles about frontend technology.
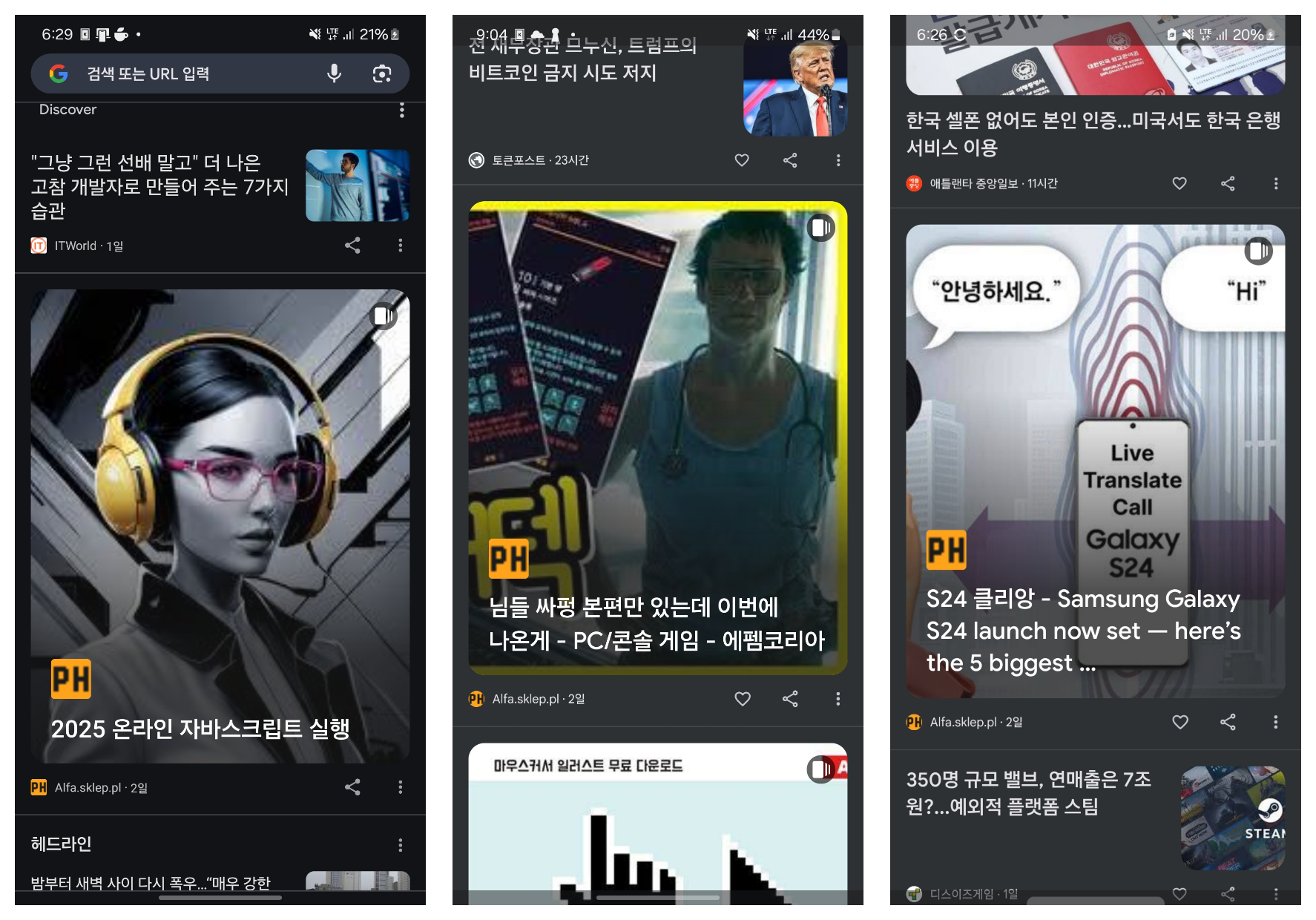
But upon clicking the articles, I was redirected to illegal gambling sites completely unrelated to the article titles. Initially, I reported these and expected them to disappear, but even after a month, the fake content kept appearing.
I considered turning off the recommendation feature, but then a thought occurred to me: “How do these fake sites manage to deceive Google and get recommended to users?”
This article documents my investigation into how scam sites are exposed in our recommended content and discusses possible ways to prevent it.
Understanding How Scam Sites Operate
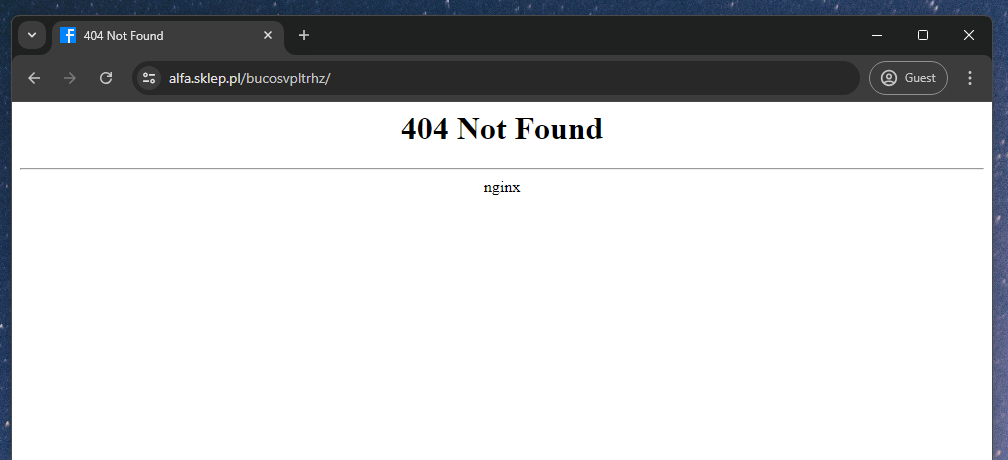
To understand how these scam sites operate, I first tried accessing the site using developer tools to check its HTML structure and JavaScript behavior. However, these scam sites were inaccessible via desktop browsers. They also couldn’t be accessed in any environment other than the Google feed. Here’s what I encountered in various environments:
- Desktop browser: 404 error
- Postman: 404 error
- Pasting the URL from Google feed into a mobile browser: 404 error
- Clicking through Google feed: Success
Although the URLs were identical in all situations, access was only possible via the Google feed, indicating that the server was likely configured to block requests from regular browsers.
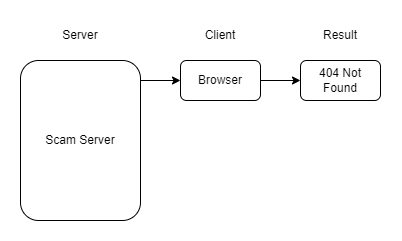
The Key is in the HTTP Headers
The issue of blocking regular browsers is likely a security measure to prevent users like me from analyzing the site. While this seemed like a difficult journey, two facts were apparent:
- The server uses Nginx.
- The server specifically recognizes access from the Google feed.
Nginx can serve different content based on the HTTP request headers, even if the request URL and method are the same. It’s likely that the server identifies requests from the Google feed by a specific header and returns the scam site’s HTML only in those cases.
To identify the ‘special header,’ the easiest method would be checking the HTTP headers of a successful request to the scam site via developer tools.
However, since desktop browser access was not possible, another approach was to intercept the network traffic on an Android OS, either through a router or another server. Examples include:
- Analyzing the packet from a smartphone request at the router level to check HTTP headers.
- Modifying the Android VM’s hosts file to proxy requests to the scam site’s domain through a local Nginx server.
I soon realized these methods wouldn’t work due to SSL certificate mismatches and the inability to intercept network packets without the certificate.
Finally, I tried using remote debugging with an Android VM and the Chrome browser. This way, I could access the network requests through the remote debugging feature.
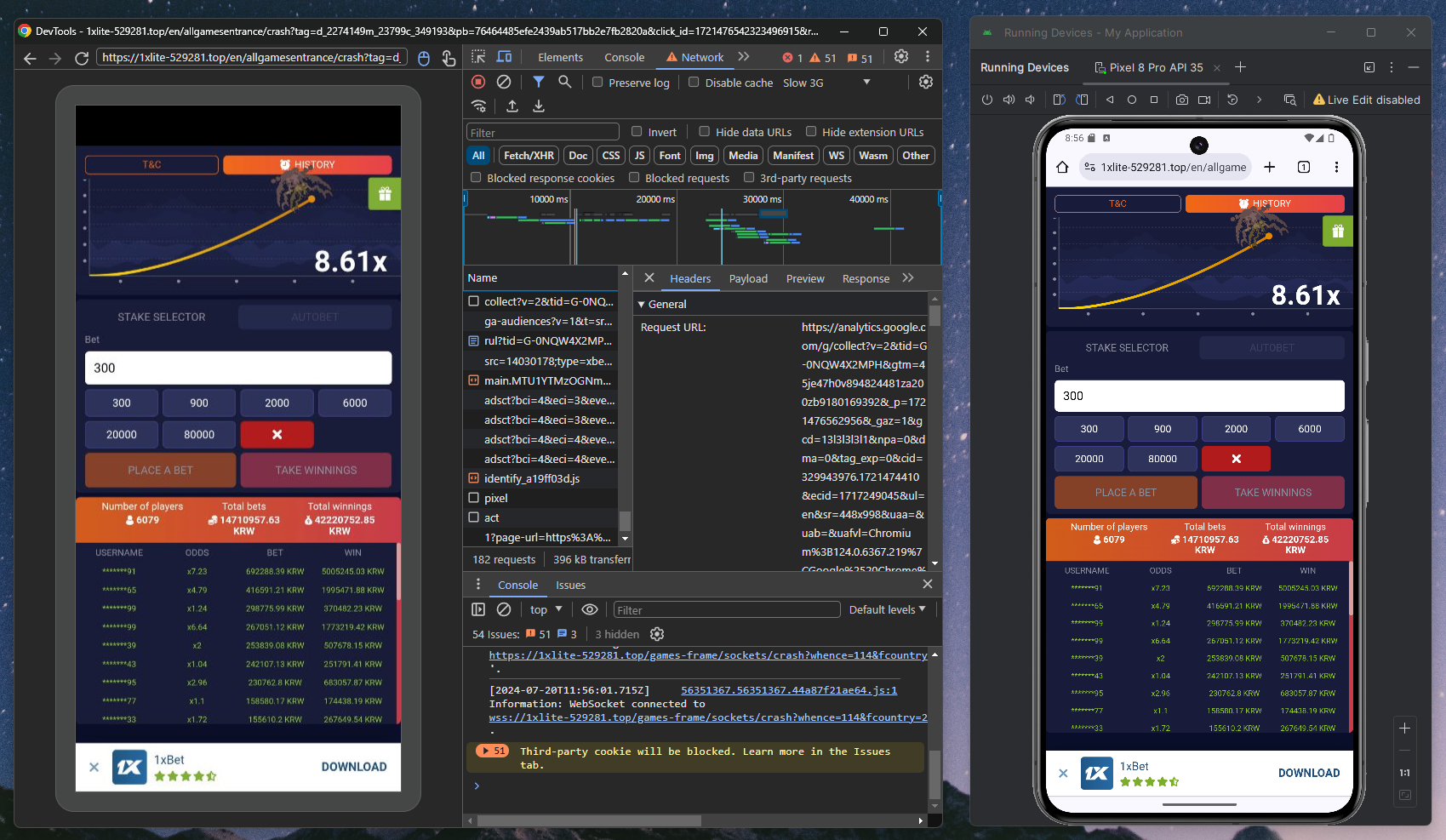
This method worked perfectly. Using the developer tools, I obtained the curl command of the request that successfully accessed the scam site. Here is the command:
curl 'https://alfa.sklep.pl/bucosvpltrhz/' \
-H 'accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7' \
-H 'accept-language: en,ja;q=0.9,ko;q=0.8,en-US;q=0.7,st;q=0.6' \
-H 'cookie: PHPSESSID=alolor9cv5glrsen734307dqkmsgegg3; fb93c=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJkYXRhIjoie1wic3RyZWFtc1wiOntcIjUxNFwiOjE3MjE0NzM5MjYsXCIzXCI6MTcyMTQ3MzkyNixcIjUxNVwiOjE3MjE0NzQwNjQsXCIxODRcIjoxNzIxNDc0MDk1fSxcImNhbXBhaWduc1wiOntcIjE5XCI6MTcyMTQ3MzkyNixcIjFcIjoxNzIxNDczOTI2fSxcInRpbWVcIjoxNzIxNDczOTI2fSJ9.ZH6vpMkY0XkaN9vZE30j_6ZQbqk7ZbFnDUyGH6TctVw; _subid=9feaq790q009' \
-H 'priority: u=0, i' \
-H 'referer: https://www.google.com/' \
-H 'sec-ch-ua: "Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"' \
-H 'sec-ch-ua-mobile: ?1' \
-H 'sec-ch-ua-platform: "Android"' \
-H 'sec-fetch-dest: document' \
-H 'sec-fetch-mode: navigate' \
-H 'sec-fetch-site: none' \
-H 'sec-fetch-user: ?1' \
-H 'upgrade-insecure-requests: 1' \
-H 'user-agent: Mozilla/5.0 (Linux; Android 10; K) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Mobile Safari/537.36'Now, I could simulate accessing the scam site from a PC. After inspecting the HTTP headers, it was clear that the server identified Google feed requests by the Referer: https://www.google.com/ header. Including this header in a Postman or curl request finally returned the HTML that redirects to the scam site.
<html>
<head>
<script type="application/javascript">
function process() {
if (window.location !== window.parent.location) {
top.location = "https://SCAM_SITE.com";
} else {
window.location = "https://SCAM_SITE.com";
}
}
window.onerror = process;
process();
</script>
</head>
<body>
The Document has moved <a href="https://SCAM_SITE.com">here</a>
</body>
</html>The returned HTML was very simple. The code merely redirects the current page to another website (an illegal gambling site). There is even a button prepared for cases where automatic redirects aren’t supported by the user’s browser.
It became clear that the server returns scam content specifically to Google feed users.
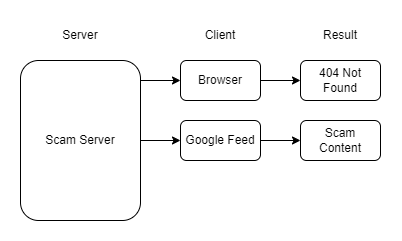
How Did They Trick the Crawler?
The final question is how these scam sites manage to rank highly and get recommended by Google’s crawlers, given their simplistic HTML content that just redirects users to other sites.
The answer lies in the HTTP headers. Search engine crawlers, like Google’s, have unique User-Agent headers. These scam sites return normal content when crawlers access them but serve scam content to users.
When a crawler visits, the scam site likely returns the following normal HTML content:
<html>
<head>
<meta name="title" content="Top 12 JavaScript Tips">
<meta name="description" content="Discover the best JavaScript tips.">
<meta property="og:title" content="Top 12 JavaScript Tips">
<meta property="og:description" content="Discover the best JavaScript tips.">
<meta property="og:image" content="/awesome-image.png">
</head>
<body>
<h1>Top 12 JavaScript Tips</h1>
<p>Discover the best JavaScript tips.</p>
...
</body>
</html>The HTML above is an example I wrote. Despite multiple attempts, I couldn’t retrieve the normal content from the scam server. It likely requires access from Google’s IP range to return the normal content.
Now, the scam site has completely deceived everyone. It has become highly ranked in Google, recommended to users, and then redirects them to illegal gambling sites. The complete picture is as follows:
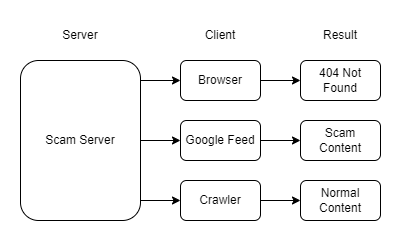
Let’s summarize the entire process of how these scam sites operate:
- Google crawlers access the scam site and receive normal content.
- The normal content gets optimized and manipulated to rank high in Google searches.
- The URL with normal images and text is shown to Google feed users.
- When users access via Google feed, they receive HTML that redirects them to an illegal site.
How Can We Prevent This?
This concludes my investigation into the scam sites I encountered on Google feed
. Surprisingly, it turns out that creating such sites is relatively simple, involving fake content and Nginx. By changing domains, they could potentially create endless scam sites.
On the other hand, it seems challenging for Google to prevent this. The only solution I could think of is to obscure crawler information and randomize the IP range. This way, scam sites wouldn’t be able to identify the crawlers. Crawlers would then receive the same scam content as users, preventing such sites from ranking high in the first place.
However, this is easier said than done. Some legitimate servers need to differentiate between crawler and user traffic and may require crawler information for specific IP range blocking. This is why Google currently discloses crawler information.
A compromise could be to maintain crawler information but set up a separate monitoring system to check if the content served to crawlers differs from what users see. Running a few anonymous crawlers alongside and comparing results might help preemptively block such scam sites.
I’ll end my article here. If you’ve faced similar issues or have solutions, please share your thoughts in the comments!